ORCJIT
本文档介绍MCJIT与ORCJIT执行的内部工作原理 engine 和 RuntimeDyld 组件。它旨在作为一个高层次实现概述,显示流程和交互对象贯穿整个代码生成和动态加载过程。
通过官方文档对MCJIT的设计与实施进行理解。
1.1 MCJIT execution engine
EngineBuilder 通常是用来创建MCJIT的执行引擎(关键?),将Module作为参数传入constructor中。然后,客户端可以设置我们控制的各种选项,然后将其传递给 MCJIT 引擎,包括选择 MCJIT 作为要创建的引擎类型。
EngineBuilder::setMCJITMemoryManager:如果客户端此时没有显式创建内存管理器,那么在实例化 MCJIT 引擎时将会创建一个默认的内存管理器(具体为SectionMemoryManager)。
将根据与用于创建EngineBuilder的模块关联的target triple创建一个新的Target Machine。
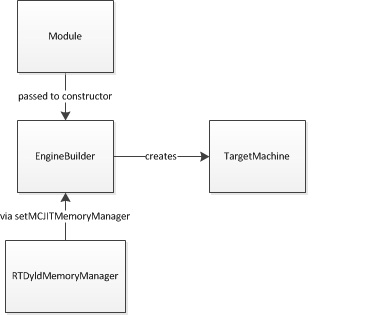
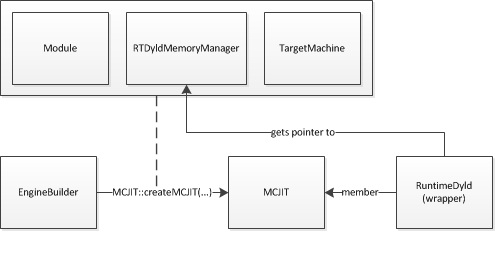
EngineBuilder::create 将调用静态 MCJIT::createJIT 函数,将其指针传递给模块、内存管理器和目标机器对象,所有这些随后都将归 MCJIT 对象所有。
MCJIT 类有一个成员变量 Dyld,它包含 RuntimeDyld 包装类的实例。此成员将用于 MCJIT 和加载对象时创建的实际 RuntimeDyldImpl 对象之间的通信。
创建后,MCJIT 持有一个指向从 EngineBuilder 接收的 Module 对象的指针,但它不会立即生成该模块的代码。代码生成会被推迟,直到显式调用 MCJIT::finalizeObject 方法或调用需要生成代码的函数(例如 MCJIT::getPointerToFunction)。
1.2 Code Generation
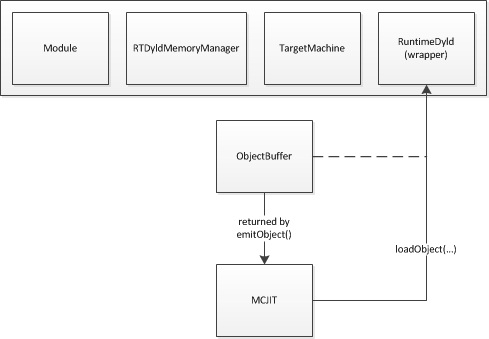
当code generation被触发时,如上所述,MCJIT 将首先尝试从其 ObjectCache 成员中检索对象映像(object image)(如果已设置)。如果无法检索缓存的object image,MCJIT将调用其emitObject方法。MCJIT::emitObject 使用本地 PassManager 实例并创建一个新的 ObjectBufferStream 实例,在对创建它的模块调用 PassManager::run 之前,将这两个实例传递给 TargetMachine::addPassesToEmitMC。
PassManager::run 调用导致 MC code generation发出完整的可重定位二进制对象映像(a complete relocatable binary object image)(采用 ELF 或 MachO 格式,具体取决于目标)到ObjectBufferStream,它被刷新以完成该过程。如果正在使用 ObjectCache,则映像(image)将被传递到此处的 ObjectCache。
在这点,ObjectBufferStream实例包含了这个原始object image。在代码被执行之前,必须将该image中的代码和数据部分加载到合适的内存中,必须应用重定位,并且必须完成内存许可和代码缓存失效(如果需要)**—code cache manager**。
1.3 Object Loading
我们无论是通过code generation还是Object Cache获取Object image,它都会被传递到 RuntimeDyld 进行加载。RuntimeDyld wrapper class检查对象以确定其文件格式,并创建 RuntimeDyldELF 或 RuntimeDyldMachO(两者均派生自 RuntimeDyldImpl 基类)的实例,并调用 RuntimeDyldImpl::loadObject 方法来执行实际加载。
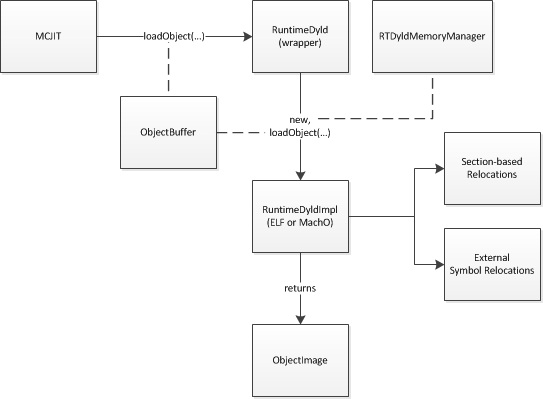
RuntimeDyldImpl::loadObject 首先从它接收到的 ObjectBuffer 创建一个 ObjectImage 实例。ObjectImage 包装了 ObjectFile 类,是一个辅助类,它解析二进制object image并提供对特定于格式的标头中包含的信息的访问,包括节、符号和重定位信息。
然后 RuntimeDyldImpl::loadObject 迭代image中的符号。收集有关常见符号的信息以供以后使用。对于每个函数或数据符号,相关联的部分被加载到存储器中,并且符号被存储在符号表映射数据结构中。迭代完成后,将生成公共符号的部分。
接下来,RuntimeDyldImpl::loadObject 迭代object image中的各个部分,并针对每个部分迭代该部分的重定位。对于每个重定位,它调用特定于格式的 processRelocationRef 方法,该方法将检查重定位并将其存储在两个数据结构之一中:基于节的重定位列表映射和外部符号重定位映射。
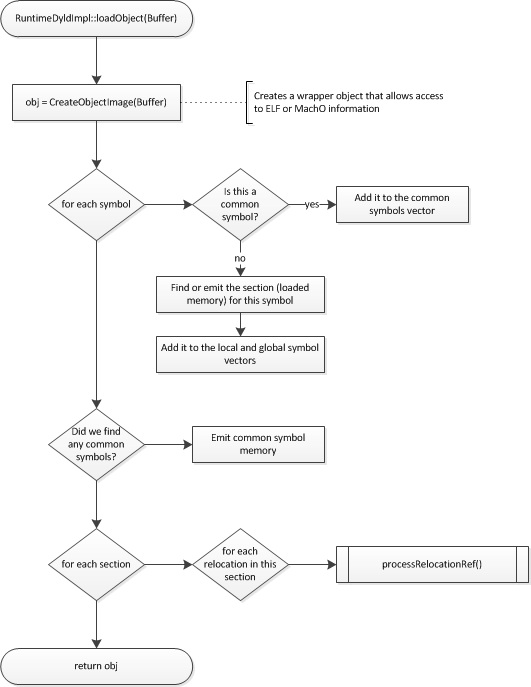
当 RuntimeDyldImpl::loadObject 返回时,该object的所有代码和数据部分都将被加载到内存管理器分配的内存中,并且重定位信息将已准备好,但重定位尚未应用,生成的代码仍然是还没有准备好被执行。
现在当 loadObject 完成时,MCJIT 引擎将立即应用重定位。然而,这不应该发生。由于代码可能是为远程目标生成的,因此应让客户端有机会在应用重定位之前重新映射节地址。可以多次应用重定位,但在要重新映射地址的情况下,第一次应用是浪费精力。
1.4 Address Remapping
在生成初始代码之后和调用 FinalizeObject 之前的任何时间,客户端都可以重新映射object中section的地址。通常这样做是因为代码是为外部进程生成的,并且被映射到该进程的地址空间。客户端通过调用 MCJIT::mapSectionAddress 重新映射section地址。这应该在section内存复制到新位置之前发生。
当调用 MCJIT::mapSectionAddress 时,MCJIT 会将调用传递给 RuntimeDyldImpl(通过其 Dyld 成员)。RuntimeDyldImpl 将新地址存储在内部数据结构中,但此时不更新代码,因为其他部分可能会更改。
当客户端完成重新映射节地址后,它将调用 MCJIT::finalizeObject 来完成重新映射过程。
1.5 Final Preparations
当调用 MCJIT::finalizeObject 时,MCJIT 调用 RuntimeDyld::resolveRelocations。此函数将尝试定位任何外部符号,然后应用该对象的所有重定位。
外部符号通过调用内存管理器的 getPointerToNamedFunction 方法来解析。内存管理器将返回目标地址空间中所请求符号的地址。 (注意,这可能不是主机进程中的有效指针。)然后,RuntimeDyld 将迭代其存储的与该符号关联的重定位列表,并调用resolveRelocation 方法,该方法通过特定于格式的实现将重定位应用于加载的节内存。
接下来,RuntimeDyld::resolveRelocations 迭代节列表,并为每个节迭代已保存的重定位列表,这些重定位引用该符号并为此列表中的每个条目调用resolveRelocation。这里的重定位列表是重定位的列表,对于该重定位,与该重定位关联的符号位于与该列表关联的部分中。这些位置中的每一个都将有一个应用重定位的目标位置,该目标位置可能位于不同的部分。

如上所述应用重定位后,MCJIT 调用 RuntimeDyld::getEHFrameSection,如果返回非零结果,则将节数据传递到内存管理器的 registerEHFrames 方法。这允许内存管理器调用任何所需的特定于目标的函数,例如使用调试器注册 EH 帧信息。
最后,MCJIT 调用内存管理器的 FinalizeMemory 方法。在此方法中,内存管理器将在必要时使目标代码缓存无效,并将最终权限应用于为代码和数据内存分配的内存页。
本文档旨在提供 ORC JIT API 的设计和实现的高级概述。
2.1 features
JIT-linking:ORC 提供API在运行时将可重定位目标文件(COFF、ELF、MachO)链接到目标进程。
LLVM IR compilation:ORC提供现成的组件(IRCompileLayer, SimpleCompiler, ConcurrentIRCompiler)来将LLVM IR加入JIT进程。
**Eager and lazy compilation:**默认情况下,一旦在 JIT 会话对象 (ExecutionSession) 中查找到符号,ORC 就会对其进行编译。
Support for Custom Compilers and Program Representations:客户端可以为他们在 JIT 会话中定义的每个符号提供自定义编译器。当需要符号的定义时,ORC 将运行用户提供的编译器。ORC 实际上完全与语言无关:LLVM IR 没有经过特殊处理,而是通过用于自定义编译器的相同包装器机制(MaterializationUnit 类)来支持。
Concurrent JIT****’d code and Concurrent Compilation:JIT 代码可以在多个线程中执行,可以产生新线程,并且可以从多个线程同时重新进入 ORC(例如,请求延迟编译)。我的 ORC 启动的编译器可以同时运行(前提是客户端设置了适当的调度程序)。内置依赖项跟踪可确保 ORC 不会释放指向 JIT 代码或数据的指针,直到所有依赖项也都已进行 JIT 且可以安全调用或使用。
Removable Code:JIT 程序表示的资源
Orthogonality and Composability:上述每个功能都可以独立使用。可以将 ORC 组件组合在一起,形成non-lazy, in-process, single threaded JIT或a lazy, out-of-process, concurrent JIT,或介于两者之间的任何形式。
2.2 LLJIT and LLLazyJIT
ORC 提供了两个现成的基本 JIT 类。它们既可以作为如何组装 ORC 组件来生成 JIT 的示例,也可以作为早期 LLVM JIT API(例如 MCJIT)的替代品。
LLJIT 类使用 IRCompileLayer 和 RTDyldObjectLinkingLayer 来支持 LLVM IR 的编译和可重定位目标文件的链接。所有操作都在symbol lookup时立即地执行(即,一旦您尝试查找其地址,就会编译symbol的定义)。在大多数情况下,LLJIT 是 MCJIT 的合适替代品(注意:尚不支持一些更高级的功能,例如 JITEventListener)。
LLLazyJIT 扩展了 LLJIT 并添加了 CompileOnDemandLayer 以启用 LLVM IR 的延迟编译。当通过 addLazyIRModule 方法添加 LLVM IR 模块时,该模块中的函数体在首次调用之前不会被编译。LLLazyJIT 旨在提供 LLVM 原始(MCJIT 之前)JIT API 的替代品。
1 | // Try to detect the host arch and construct an LLJIT instance. |
构建器类提供了许多可以在构造 JIT 实例之前指定的配置选项。允许我们构造许多不同种的JIT。
1 | // LLVM_LIB_EXECUTIONENGINE_MCJIT_MCJIT_H |
2.3 Design Overview
ORC 的 JIT 程序模型旨在模拟静态和动态链接器使用的链接和符号解析规则。这允许 ORC JIT 任意 LLVM IR,包括由普通静态编译器(例如 clang)生成的 IR,该编译器使用symbol链接和可见性等构造,以及weak和common symbol定义。
要了解其工作原理,请想象一个程序 foo 链接到一对动态库:libA 和 libB。在命令行上,构建该程序可能如下所示:
1 | $ clang++ -shared -o libA.dylib a1.cpp a2.cpp |
这个例子没有告诉我们编译如何或何时发生。这将取决于假设的 CXXCompilingLayer 的实现。然而,无论该实现如何,相同的基于链接器的符号解析规则都将适用。例如,如果 a1.cpp 和 a2.cpp 都定义了函数“foo”,则 ORCv2 将生成重复定义错误。另一方面,如果a1.cpp和b1.cpp都定义了“foo”,则没有错误(不同的动态库可能定义相同的符号)。如果 main.cpp 引用“foo”,它应该绑定到 LibA 中的定义而不是 LibB 中的定义,因为 main.cpp 是“main”dylib 的一部分,并且main dylib 在 LibB 之前链接到 LibA。
许多 JIT 客户端不需要严格遵守通常的ahead-of-time linking规则,并且应该能够通过将所有代码放入单个 JITDylib 中来顺利完成。然而,想要为传统上依赖ahead-of-time linking(例如 C++)的语言/项目进行 JIT 编码的客户会发现此功能使生活变得更加轻松。
除了提供符号地址之外,ORC 中的符号查找还有另外两个重要功能:**(1) 它触发所搜索符号的编译(如果尚未编译),(2)提供并发编译的同步机制。**查找过程的伪代码是:
1 | construct a query object from a query set and query handler |
在这种情况下,materializers 是根据请求提供符号的工作定义的东西。通常materializers只是编译器的包装器,但它们也可以直接包装 jit-linker(如果支持定义的程序表示是object文件),或者甚至可能是直接将位写入内存的类(例如,如果 定义是stubs)。materializers是生成可安全调用或访问的符号定义所需的任何操作(compiling, linking, splatting bits, registering with runtimes等)的总称。
当每个materializer完成其工作时,它会通知 JITDylib,JITDylib又通知正在等待新的materialized definitions的任何查询对象。每个查询对象都维护着一个仍在等待的symbol数量的计数,一旦这个计数达到零,查询对象就会使用一个SymbolMap(symbol名称到地址的映射)调用查询处理程序,描述结果。如果任何符号未能materialize,查询将立即使用错误调用查询处理程序。 收集到的materialization units被发送到ExecutionSession进行调度,调度行为可以由客户端设置。默认情况下,每个materialization在调用线程上运行。客户端可以自由地创建新线程来运行materialization,或者将工作发送到线程池的工作队列(这是LLJIT/LLLazyJIT的做法)。
2.4 Top Level APIs
- ExecutionSession 表示 JIT 程序并为 JIT 提供上下文:它包含 JITDylib、错误报告机制并调度materializers。
- JITDylibs 提供符号表。
- Layers (ObjLinkingLayer 和 CXXLayer)是编译器的包装器(wrappers),允许客户端将这些编译器支持的未编译程序表示添加到 JITDylibs。
- ResourceTrackers 允许您删除代码。
JIT clients need not be aware of them, but Layer authors will use them:
- **MaterializationUnit:**当调用 XXXLayer::add 时,它将给定的程序表示形式(在本例中为 C++ 源代码)包装在 MaterializationUnit 中,然后存储在 JITDylib 中。MaterializationUnits 负责描述它们提供的定义,并在需要编译时解包程序表示并将其传递回层(这种所有权改变使得编写线程安全层变得更容易,因为程序表示的所有权将被传回到堆栈上,而不是必须从 Layer 成员中取出,这需要同步)。
- **MaterializationResponsibility:**当 MaterializationUnit 将程序表示返回层时,它会附带一个关联的 MaterializationResponsibility 对象。 该object tracks必须Materialization的定义,并提供一种在成功materialized或发生失败时通知 JITDylib 的方法。
2.5 Absolute Symbols, Aliases, and Reexports
ORC 可以轻松地定义具有绝对地址的符号,或者只是其他符号的别名的符号:
2.5.1 Absolute Symbols
绝对符号是直接映射到地址而不需要进一步materialization的符号,例如:“foo”= 0x1234。绝对符号的一种用例是允许解析过程符号。
1 | JD.define(absoluteSymbols(SymbolMap({ |
通过这种映射,添加到 JIT 的已建立代码可以象征性地引用 printf,而不需要“baked in”printf 的地址。这反过来又允许 JIT 代码(例如编译对象)的缓存版本在 JIT 会话中重复使用,因为 JIT 代码不再更改,只有绝对符号定义发生更改。
对于进程和库符号,DynamicLibrarySearchGenerator utility( How to Add Process and Library Symbols to JITDylibs)可用于自动为您构建绝对符号映射。然而,absoluteSymbols 函数对于使 JIT 中的非全局对象对 JIT 代码可见仍然很有用。例如,假设您的 JIT 标准库需要访问您的 JIT 对象才能进行一些调用。我们可以将对象的地址bake到库中,但随后需要为每个会话重新编译它:
1 | // From standard library for JIT'd code: |
我们可以将其转换为 JIT 标准库中的符号引用:
1 | extern MyJIT *__MyJITInstance; |
然后在 JIT 启动时使用绝对符号定义使我们的 JIT 对象对 JIT 标准库可见:
1 | MyJIT J = ...; |
2.5.2 Aliases and Reexports
Aliases and reexports允许您定义映射到现有符号的新符号。这对于更改跨会话的符号之间的链接关系非常有用,而无需重新编译代码。例如,假设 JIT 代码可以访问日志函数 void log(const char*),JIT 标准库中有两个实现:log_fast 和 log_detailed。您的 JIT 可以通过在 JIT 启动时设置别名来选择在引用日志符号时使用这些定义中的哪一个:
1 | auto &JITStdLibJD = ... ; |
symbolAliases 函数允许您在单个 JITDylib 中定义别名。 reexports 函数提供相同的功能,但跨 JITDylib 边界进行操作。例如:
1 | auto &JD1 = ... ; |
eexports 实用程序可以方便地通过从其他几个 JITDylib 重新导出符号来构建单个 JITDylib 接口。
2.6 Laziness
ORC 中的Laziness是由名为“lazy reexports”的实用程序提供的。Laziness重新导出类似于常规重新导出或别名:它为现有符号提供新名称。然而,与常规重新导出不同,Laziness重新导出的查找不会立即触发重新导出符号的materialization。相反,它们仅触发函数stub的materialization。该函数stub被初始化为指向lazy call-through,它提供了对 JIT 的重入。如果在运行时调用stub,则lazy call-through将查找reexported symbol(如有必要,会触发其materialization),更新stub(在后续调用中直接调用reexported symbol),然后通过reexported symbol返回。通过重用现有的symbol查找机制,lazy reexports继承了相同的并发保证。对lazy reexports的调用可以同时从多个线程进行,并且重新导出的符号可以是任何编译状态(uncompiled, already in the process of being compiled, or already compiled),并且调用将成功。这允许laziness与远程编译、并发编译、并发 JIT 代码和推测编译等功能安全地混合。
一些客户必须意识到regular reexports和lazy reexports之间的另一个关键区别:lazy reexport的地址将与reexported symbol的地址不同(而regular reexport保证与reexport symbol具有相同的地址)。关心指针相等性的客户端通常希望使用reexport的地址作为reexported symbol的规范地址。这将允许在不强制materialization of the reexport的情况下获取地址
如果 JITDylib JD 包含符号 foo_body 和 bar_body 的定义,我们可以通过调用以下命令在 JITDylib JD2 中创建惰性入口点 Foo 和 Bar:
1 | auto ReexportFlags = JITSymbolFlags::Exported | JITSymbolFlags::Callable; |
有关如何将lazyReexports与LLJIT类一起使用的完整示例可以在llvm/examples/OrcV2Examples/LLJITWithLazyReexports中找到。
2.7 Transitioning from ORCv1 to ORCv2
自 LLVM 7.0 以来,新的 ORC 开发工作重点是添加对并发 JIT 编译的支持。 支持并发的新 API(包括新层接口和实现以及新实用程序)统称为 ORCv2,而原始的非并发层和实用程序现在称为 ORCv1。
ORCv1 和 ORCv2 之间存在一些需要注意的设计差异:
- ORCv2 完全采用从 MCJIT 开始的 JIT-as-linker 模型。 模块(和其他程序表示形式,例如Object Files)不再直接添加到 JIT 类或层。 相反,它们按层添加到 JITDylib 实例中。 JITDylib 确定定义所在的位置,层确定定义的编译方式。 JITDylib 之间的链接关系决定了如何解析模块间引用,并且不再使用符号解析器。
- 除非需要多个 JITDylib 来建立链接关系,否则 ORCv1 客户端应将所有代码放在单个 JITDylib 中。MCJIT 客户端应使用 LLJIT(请参阅 LLJIT 和 LLLazyJIT),并且可以将代码放置在 LLJIT 默认创建的主 JITDylib 中(请参阅 LLJIT::getMainJITDylib())。
- 所有 JIT 堆栈现在都需要一个 ExecutionSession 实例。 ExecutionSession 管理字符串池、错误报告、同步和符号查找。
- ORCv2 使用唯一字符串(SymbolStringPtr 实例)而不是字符串值,以减少内存开销并提高查找性能。
- IR 层需要 ThreadSafeModule 实例,而不是 std::unique_ptr
。 ThreadSafeModule 是一个包装器,可确保使用相同 LLVMContext 的模块不会同时访问。 - Symbol查找不再由层处理。相反,JITDylib 上有一个lookup方法,它需要扫描 JITDylib 列表。
- removeModule/removeObject 方法被 ResourceTracker::remove 取代。
2.8 How-tos
2.8.1 How to manage symbol strings
ORC 中的符号字符串具有独特的功能,可以提高查找性能、减少内存开销,并允许符号名称充当有效的键。要获取字符串值的唯一 SymbolStringPtr,请调用 ExecutionSession::intern 方法:
1 | ExecutionSession ES; |
如果您希望使用符号的 C/IR 名称执行查找,您还需要在驻留字符串之前应用平台链接器修饰。在 Linux 上,这种修改是无操作的,但在其他平台上,它通常涉及向字符串添加前缀(例如 Darwin 上的“_”)。修饰方案基于目标的 DataLayout。给定一个 DataLayout 和一个 ExecutionSession,您可以创建一个 MangleAndInterner 函数对象来为您执行这两项工作:
1 | ExecutionSession ES; |
2.8.2 How to create JITDylibs and set up linkage relationships
在 ORC 中,所有符号定义都驻留在 JITDylib 中。 JITDylib 是通过调用具有唯一名称的 ExecutionSession::createJITDylib 方法来创建的:
1 | ExecutionSession ES; |
JITDylib 由 ExecutionEngine 实例拥有,并在销毁时被释放。
2.8.3 How to remove code
要从 JITDylib 中删除单个模块,必须首先使用显式 ResourceTracker 添加该模块。然后可以通过调用 ResourceTracker::remove 来删除该模块:
1 | auto &JD = ... ; |
直接添加到 JITDylib 的模块将由 JITDylib 的默认resource tracker追踪。
可以通过调用 JITDylib::clear 从 JITDylib 中删除所有代码。这会使清除的 JITDylib 处于空但可用的状态。
可以通过调用 ExecutionSession::removeJITDylib 来删除 JITDylib。这会清除 JITDylib,然后将其置于失效状态。无法对 JITDylib 执行进一步的操作,并且一旦释放其最后一个句柄,它将被销毁。
有关如何使用资源管理 API 的示例可以在 llvm/examples/OrcV2Examples/LLJITRemovableCode 中找到。
2.8.4 How to add the support for custom program representation
为了添加对自定义程序表示的支持,需要用于程序表示的自定义 MaterializationUnit 和自定义层。该层将有两个操作:添加和发出。添加操作获取程序表示的一个实例,构建一个自定义的 MaterializationUnit 来保存它,然后将其添加到 JITDylib。出操作采用 MaterializationResponsibility 对象和程序表示的实例并将其materializes,通常是通过编译它并将生成的object传递给 ObjectLinkingLayer。
您的自定义 MaterializationUnit 将有两个操作:materialize 和 discard 。当查找unit提供的任何符号时,将调用materialize函数,并且它应该只调用层上的emit函数,传入给定的MaterializationResponsibility和wrapped program表示。如果不需要您的单元提供的某些weak symbol(因为 JIT 找到了重写定义),则将调用丢弃函数。您可以使用它来提前删除定义,或者直接忽略它并让链接器稍后删除定义。
下面是一个 ASLayer 的示例:
1 | // ... In you JIT class |
2.8.5 How to use ThreadSafeModule and ThreadSafeContext
ThreadSafeModule 和 ThreadSafeContext 分别是Module和 LLVMContext 的wrappers。ThreadSafeModule 是一对 std::unique_ptr
ThreadSafeContexts 可以从 std::unique_ptr
1 | ThreadSafeContext TSCtx(std::make_unique<LLVMContext>()); |
ThreadSafeModule 可以由一对 std::unique_ptr
1 | ThreadSafeModule TSM1( std::make_unique<Module>("M1", *TSCtx.getContext()), TSCtx); |
在使用 ThreadSafeContext 之前,客户端应确保上下文只能在当前线程上访问,或者上下文已锁定。 在上面的示例中(上下文从未锁定),我们依赖于 TSM1 和 TSM2 以及 TSCtx 均在一个线程上创建这一事实。 如果要在线程之间共享上下文,则必须在访问或创建附加到它的任何模块之前将其锁定。 例如。
1 | ThreadSafeContext TSCtx(std::make_unique<LLVMContext>()); |
为了使对模块的独占访问更易于管理,ThreadSafeModule 类提供了一个方便的函数 withModuleDo,它隐式地 (1) 锁定关联的上下文,(2) 运行给定的函数对象,(3) 解锁上下文,以及 (3) 返回 函数对象生成的结果。 例如。
1 | ThreadSafeModule TSM = getModule(...); |
希望最大限度地提高并发编译可能性的客户将希望在新的 ThreadSafeContext 上创建每个新的 ThreadSafeModule。 因此,提供了 ThreadSafeModule 的便捷构造函数,它从 std::unique_ptr
1 | // Maximize concurrency opportunities by loading every module on a |
计划运行单线程的客户端可以选择通过在同一上下文中加载所有模块来节省内存:
1 | // Save memory by using one context for all Modules: |
2.8.6 How to Add Process and Library Symbols to JITDylibs
JIT 代码可能需要访问主机程序或支持库中的符号。 启用此功能的最佳方法是将这些符号反映到您的 JITDylib 中,以便它们看起来与执行会话中定义的任何其他符号相同(即它们可以通过 ExecutionSession::lookup 找到,因此在链接期间对 JIT 链接器可见) 。
反映外部符号的一种方法是使用absoluteSymbols函数手动添加它们:
1 | const DataLayout &DL = getDataLayout(); |
如果要反映的符号集较小且固定,则使用absoluteSymbols 是合理的。另一方面,如果符号集很大或可变,那么由definition generator按需添加定义可能更有意义。definition generator是一个可以附加到 JITDylib 的对象,只要该 JITDylib 中的查找未能找到一个或多个符号,它就会接收回调。在查找继续之前,定义生成器有机会生成缺失符号的定义。
ORC 提供了 DynamicLibrarySearchGenerator 实用程序,用于为您反映进程(或特定动态库)中的符号。例如,要反映运行时库的整个接口:
1 | const DataLayout &DL = getDataLayout(); |
DynamicLibrarySearchGenerator 实用程序还可以使用过滤器函数来构造,以限制可能反映的符号集。例如,要从主进程公开一组允许的符号:
1 | const DataLayout &DL = getDataLayout(); |
对进程或库符号的引用也可以使用符号的原始地址硬编码到 IR 或对象文件中,但是应该首选使用 JIT 符号表的符号解析:它使 IR 和对象在后续 JIT 会话中保持可读和可重用。Hardcoded地址难以阅读,并且通常仅适用于一次会话。