UQBT
UQBT: Adaptable Binary Translation at Low Cost 论文笔记
在描述机器和操作系统特性的规范的基础上来构建一个二进制翻译器,这种静态二进制转换框架支持各种处理器,包括复杂指令集计算机(CISC)、简化指令集计算机(RISC)和基于堆栈的机器。
Design Goals
主流的二进制翻译器都受制于目标机器(需要针对目标机器进行针对化设计),导致开发成本高。UQBT的各个组件都经过精细化开发,实现可以在不同机器上进行重用。
目标:UQBT是一个retargetable and re-sourceable的二进制翻译器(既可以改变源机器又可以改变目标机器)
思想:将machine-dependent和machine-independent的问题进行分离。对于machine-dependent问题则通过描述(或规范)语言支持依赖相关的组件(具体就是将其抽象为某种中间语言),对于machine-independent问题则可以直接复用。
缺陷:(一)解决了指令集、中间值(数据的字节顺序)约定、调用约定和二进制文件格式的差别,但未解决操作系统层面的差别(ABI和系统调用?)。(二)处理用户代码(应用程序),但不处理内核代码或动态链接的库。
准备看看后续的SBT是如何解决上述的问题,关键是内核代码和动态链接库的处理。
Design
Support multiple machine inexpensively
分为三个阶段:解码-分析-编码 (分别对应decoder、analysis和encoder三个组件),前端解码源二进制文件,分析器对程序的表现形式进行转化(IR形式),后端优化编码生成新的二进制文件。
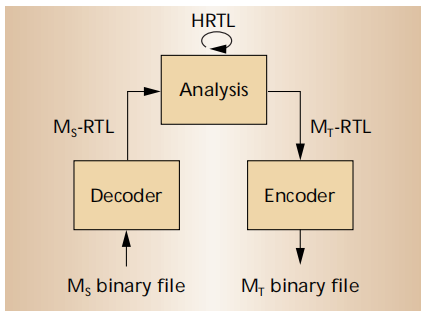
解码器将其转换为IR的形式,UQBT中主要分为两种RTLs和HRTL:
RTLs(register transfer lists):用来描述机器指令对寄存器的影响,就是说将机器指令转换为一系列对寄存器的操作,并且通过RTLs这个IR进行表示便于后续的处理。(每个机器的RTLs都是不一样的,machine-dependent)
HRTL(Higher-Level Register Transfer Language ):同样也是描述寄存器操作,支持基本控制传输(条件和无条件跳转、调用和返回)和无限数量的寄存器。(每个机器的HRTL都是一样的,machine-independent)
一个机器的指令集包括:语法(与哪个装配指令相匹配),语义(一个特定的装配指令意味着什么),控制传输指令(哪个指令改变程序的控制流程以及如何进行),以及它的延迟控制传输。
UQBT使用不同的语言对特性进行了描述:
Specification Language for Encoding and Decoding (SLED) :语法(syntax)
Semantic Specification Language (SSL) :语义(semantics)
Control-Transfer Language (CTL): 控制传输指令(control-transfer)
Delayed Control-Transfer Language(DCTL): 延迟传输(delayed control transfer)
操作系统的约定和格式以调用约定(call convention)的形式出现,包括参数传递的位置(例如,堆栈或寄存器)、进程堆栈帧的描述和本地变量所在的位置,以及操作系统所要求的二进制文件格式(binary format)。
UQBT使用不同的IR对特性进行了描述:
Procedure Abstraction Language(PAL):call convention
Binary File Format (BFF) : binary format
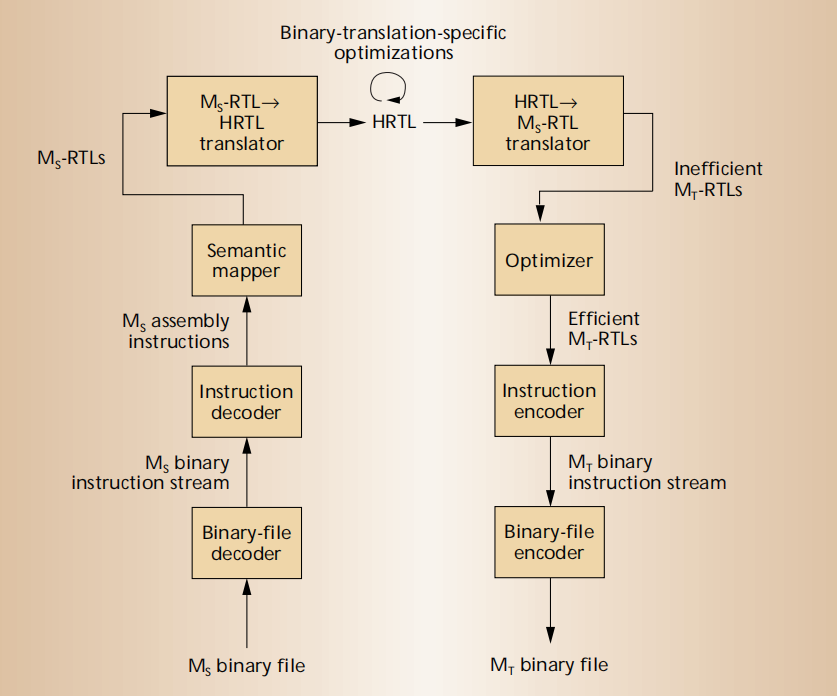
下述内容与上图直接相关
Decoding binary code to Ms-RTLs
主要可以分为三步:
一、将源二进制文件解码放入二进制文件解码器(binary-file decoder)生成二进制指令流,并将二进制指令流提供给指令解码器。描述二进制文件格式内容来构建解码器(ELF,PE等)
二、指令解码器(instruction decoder)将指令流的的每条指令和操作进行识别,使用the New Jersey Machine-Code的工具包根据SLED规范自动生成解码器的一部分。
三、语义映射器(semantic mapper)将每个指令以Ms-RTL的形式映射到其语义表示中。SSL通过将每条指令与一个Ms-RTL相关联,来驱动语义映射器。
二进制文件变**指令流->解析指令流->具体为寄存器操作**
Translating MS-RTLs up to HRTL
识别间接控制传输的目标,将基本控制传输转换为HRTL指令,并确定过程调用的参数和返回位置。例如将Pentium基于堆栈的浮点指令转换为flat寄存器模型实现复用。
Control transfers
使用CTL来实现对有条件的或无条件的跳转、调用和返回的转换。call mapping仅仅识别调用指令本身,然后通过Ms-RTLs和源机器的约定对参数进行推断。
Recovering parameters and return values
UQBT使用可达性和活动性分析,根据调用约定和可以传递参数和返回值的位置来恢复参数和返回值信息。PAL指定了这些信息(指定ABI–描述了为特定操作系统所允许的调用约定、堆栈帧的分布、分配本地变量的位置等),并描述了过程的堆栈帧和局部变量在堆栈上的有效位置。
UQBT对调用者和被调用者使用前语和后语(短习语指令序列)的概念。对于被调用者来说,前语和后语分别代表函数的开头和结尾。对于调用者来说千语是自身,后语为调用之后的清理工作。

Incoming parameters会针对性进行偏移一个simm13的量,%afp是一个抽象帧指针来作为栈帧的参照。

将其进行等价为HRTL
Type analysis
UQBT主要分析区分四个类型:整数、浮点值、指向数据的指针和指向代码的指针(包含他们的大小和符号),四个类型足以用来进程的参数和返回值。使用RTLs中的等价语义替换对helper routine的调用。
Manipulating HRTL
同样转换为HRTL是有利的,能够共用一个翻译器的后端,并且能够使用目标机器的相关约定。此外还可以允许将特定于二进制转换的优化插入到UQBT框架中
Translating HRTL down to binary code
接口到Zephyr project的一部分,然后对HRTL进行翻译。将生成的代码和数据放到各种C和汇编文件中,这些文件可以用目标机器的任何C编译器和汇编器进行编译。每个函数都用一个低级的C文件来表示。对于每个数据部分,UQBT将生成一个汇编文件。并且使用makefile对文件进行打包,以便于针对更为复杂的程序。
Interpretation hooks
在静态二进制翻译中需要解释器或者仿真器对运行在发现的未翻译的代码进行处理,解释器直接使用Ms->Mt的映射,这个映射表直接存储在目标二进制文件中,并且会将源代码部分文本也放在目标二进制文件中。
Target binaries
静态二进制翻译无法解决全部的问题,所以UQBT将数据部分复制到目标二进制文件中,这些数据通过映射器保存为源文件中的虚拟地址(便于直接查找)。
EXPERIENCE WITH THE UQBT FRAMEWORK
Translation quality
对于同ISA的翻译,执行速度基本一致。Sparc和Pentium,对于缺乏显著静态数据处理的程序,翻译后程序性能更好。对于静态数据处理较多的速度降低1.2到2倍(与大端存储和小端存储相关)。
大端与小端存储的区别和意义?
Effort
架构化,帮助开发者减少对二进制翻译器的开发工作量,节约时间成本,其次架构可以重复使用。
conclusion
UQBT项目验证了通过使用规范以低成本支持各种机器来创建适应性强的二进制翻译环境的可行性。